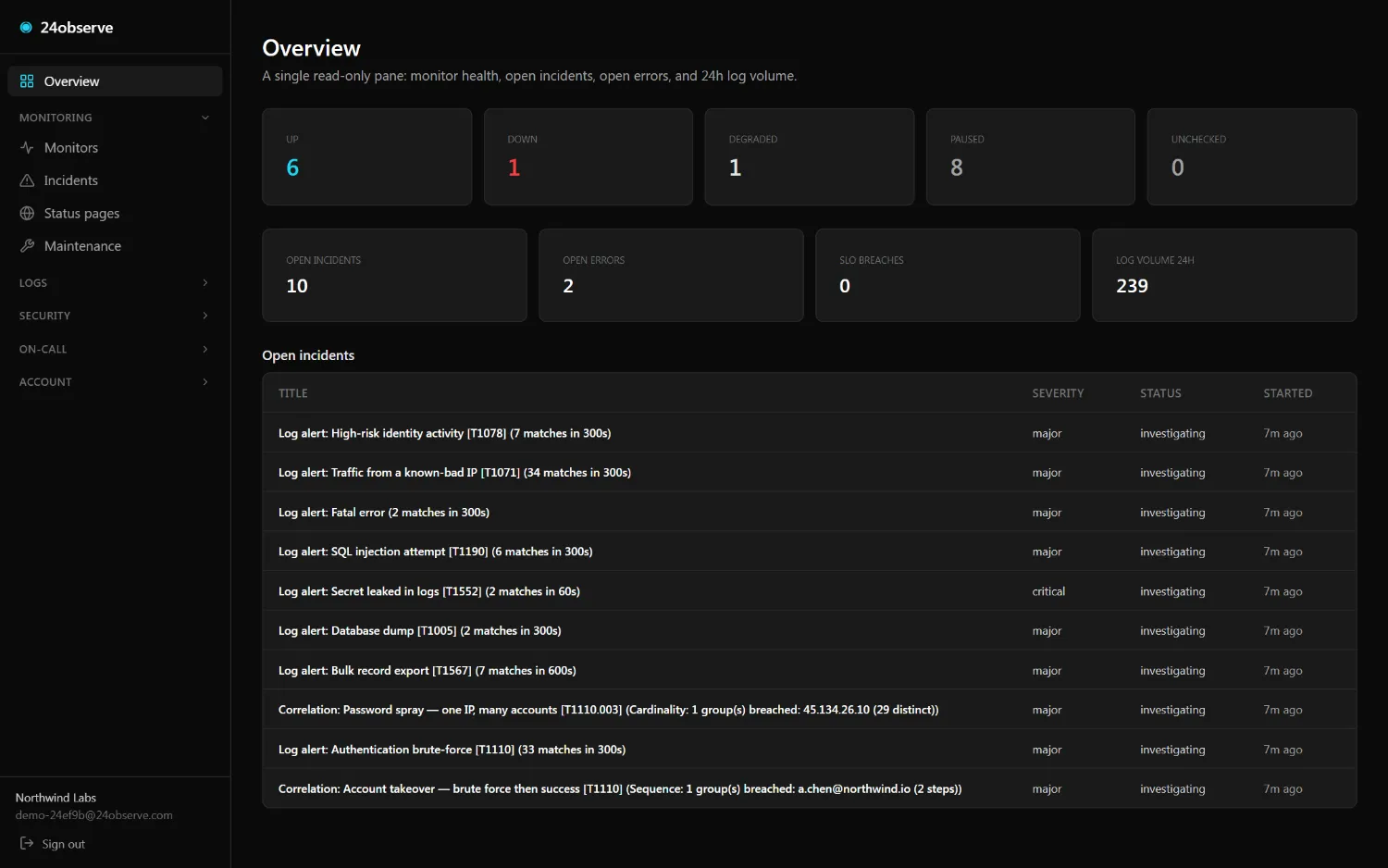
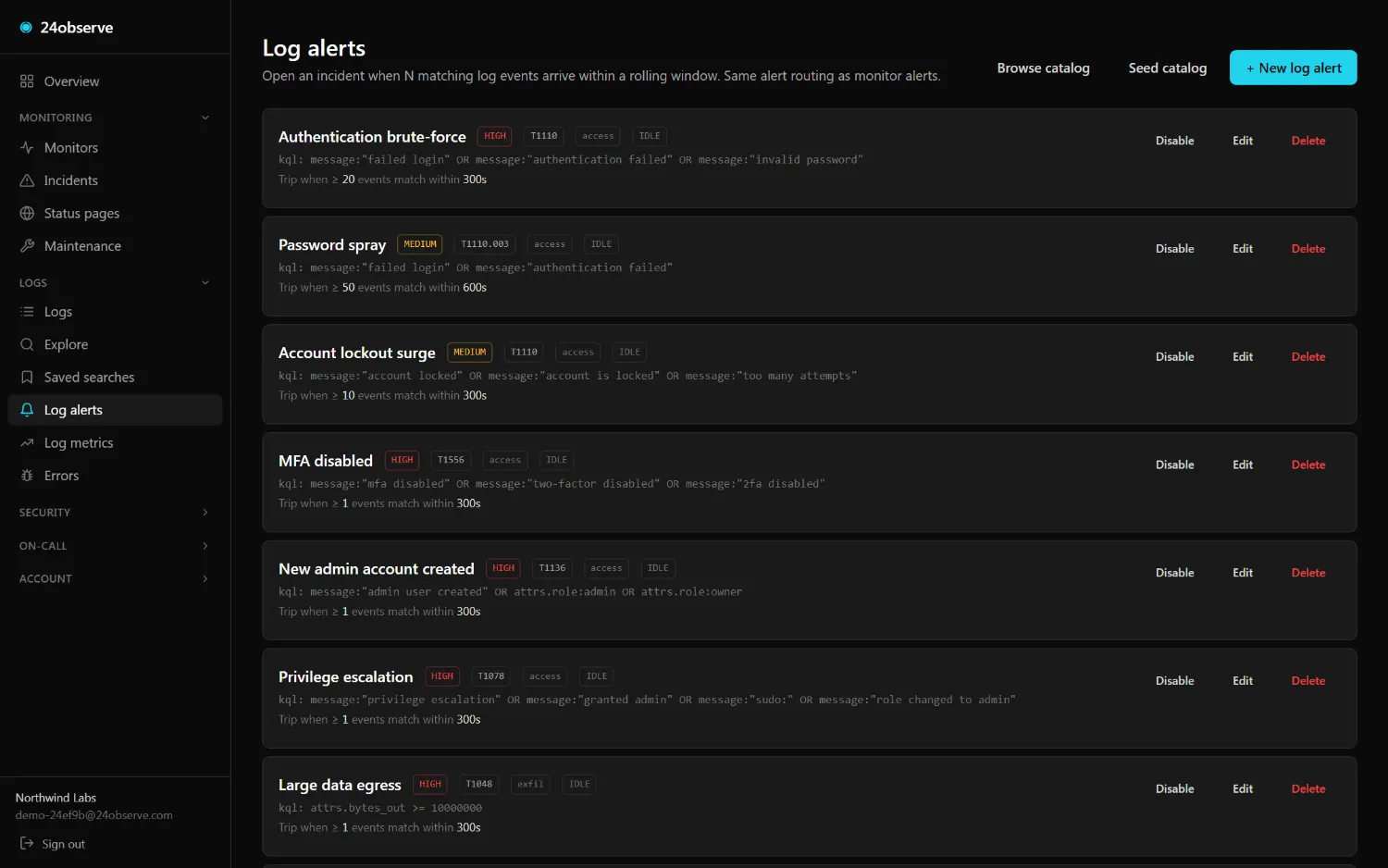
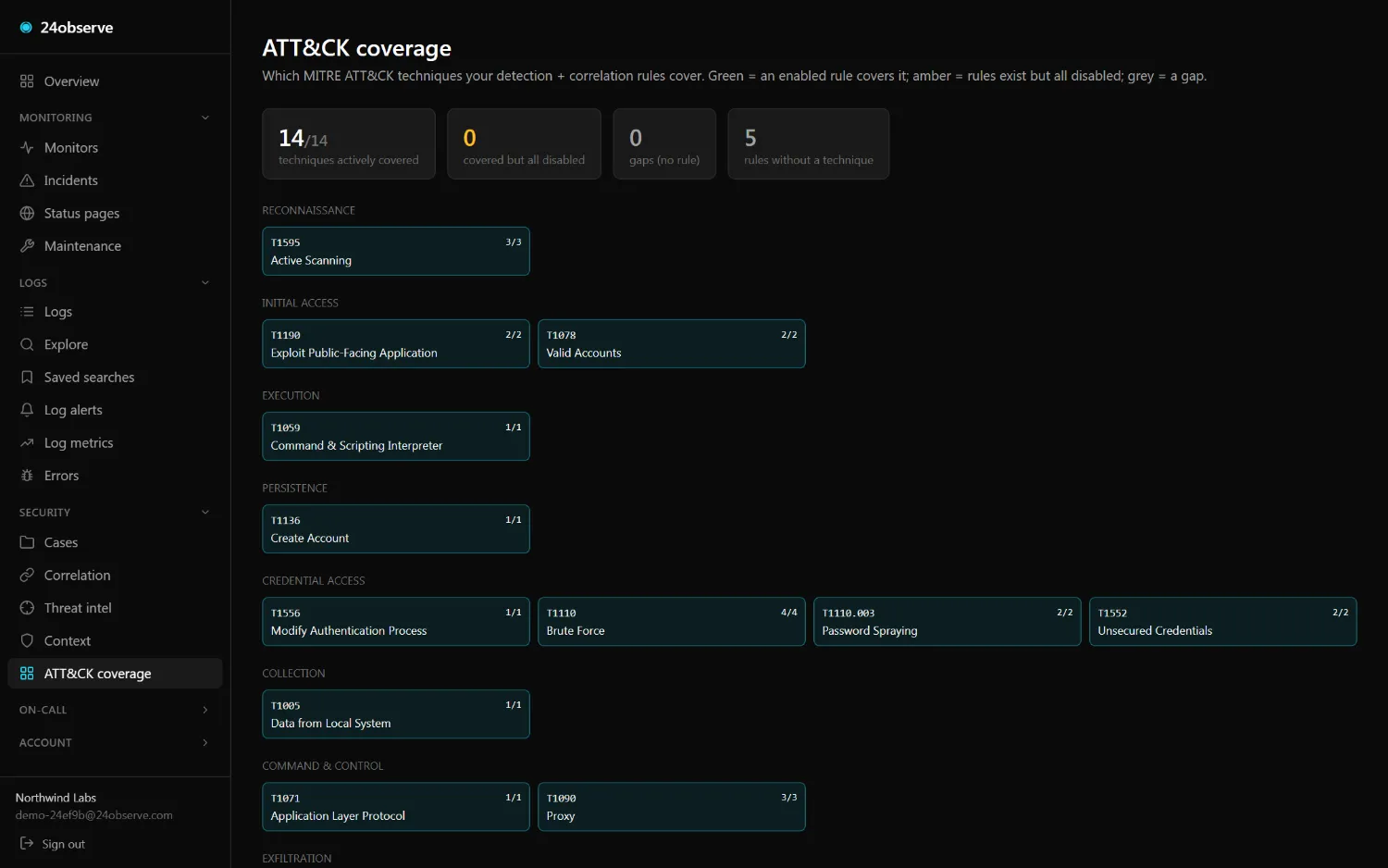
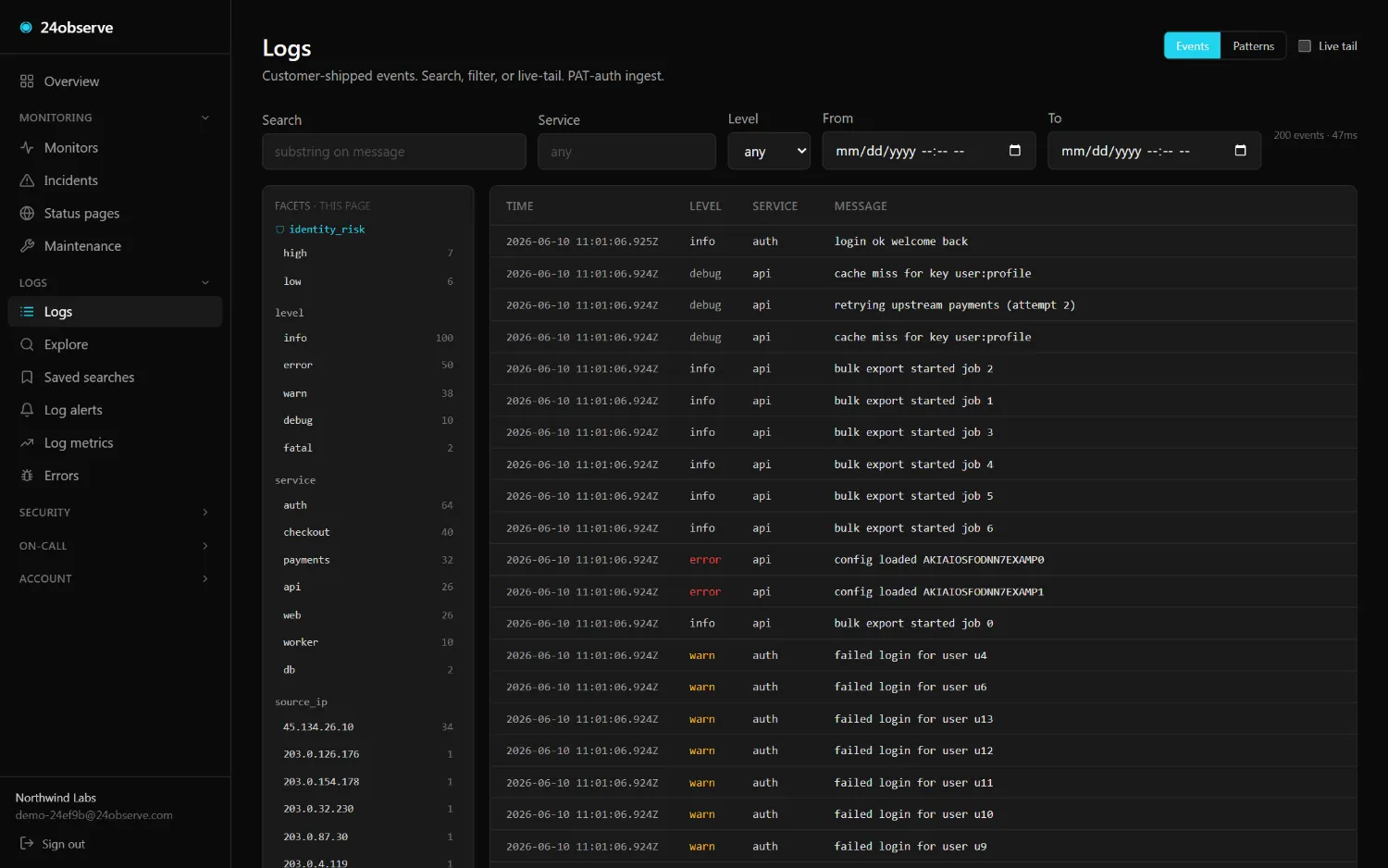
Most "observability + security" stories are two products and two bills. Here a
detection is just another rule that opens an incident — same alerting, same cases,
same API. Threat-intel and enrichment run inline at ingest, so the signal is already
on the event by the time a rule looks at it.
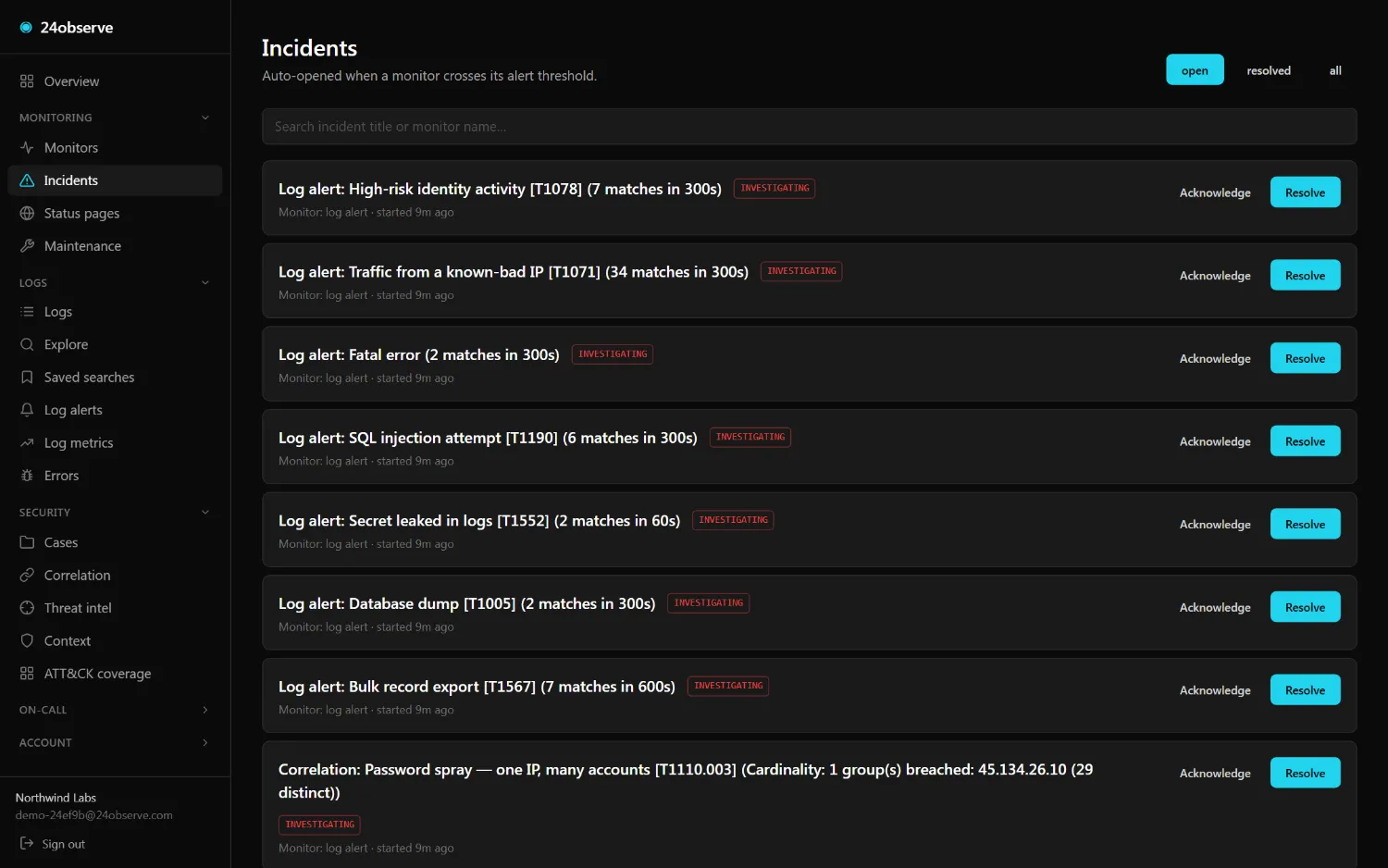
01 / DETECT
41 detections, ATT&CK-tagged
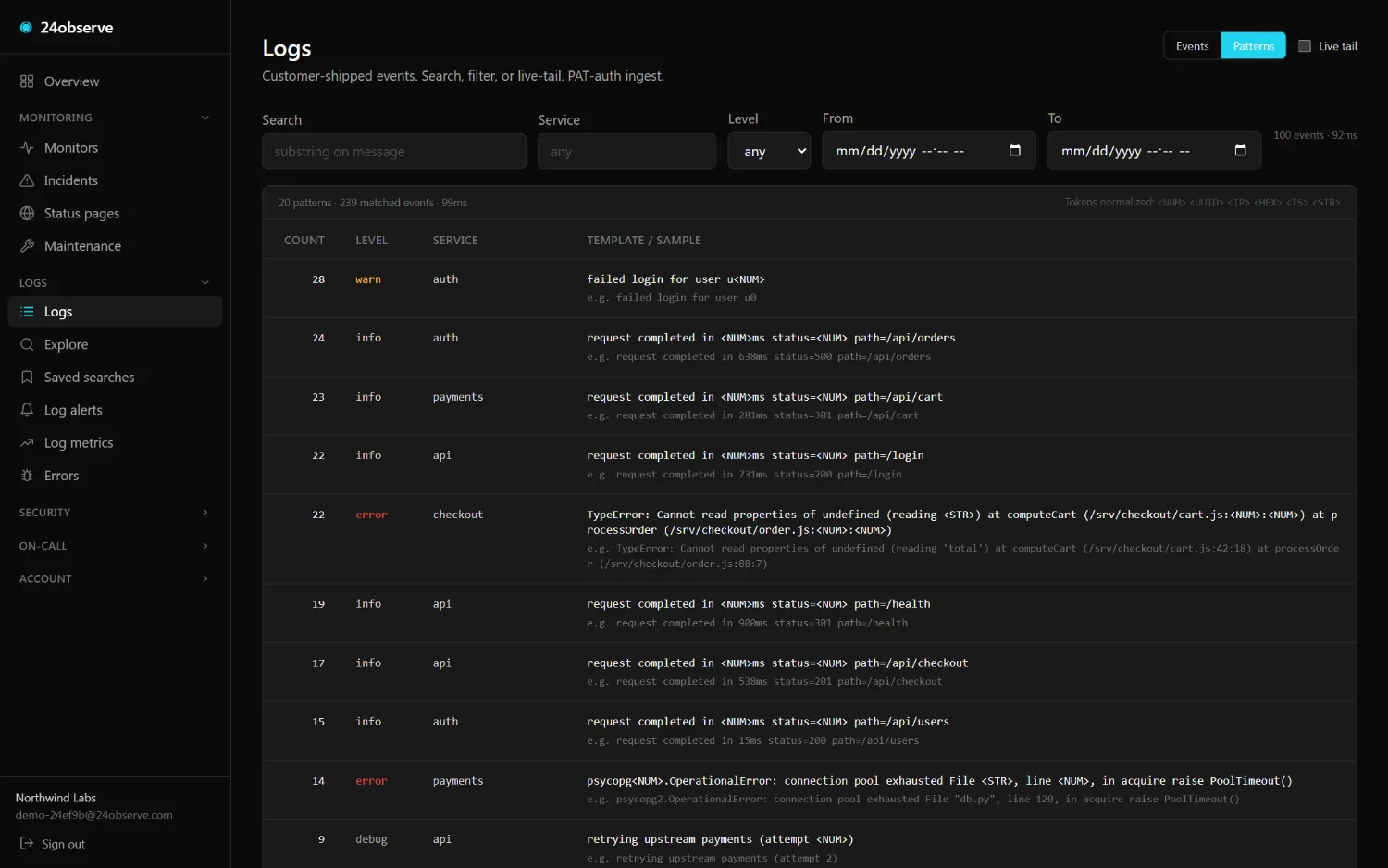
Prebuilt rules across access, exfil, secrets, web-attacks, reliability, threat-intel, AI-agent security, and MCP traffic — each carrying its MITRE ATT&CK technique where one applies. Write your own in one line of KQL-lite. They open incidents in the same pipeline as your uptime checks.
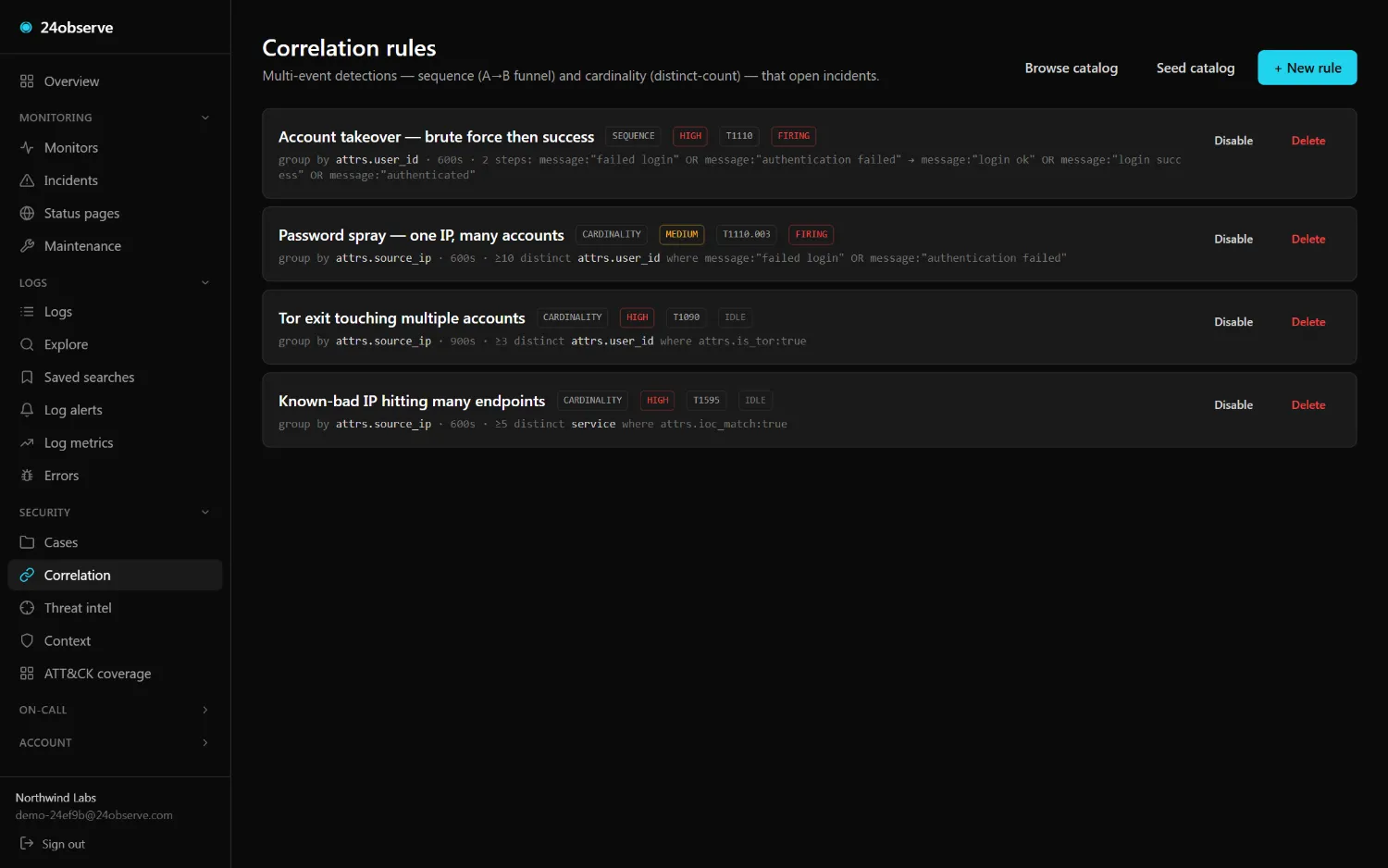
02 / CORRELATE
Multi-event correlation
The signals a single log line can't express. Sequence — failed logins then a success. Cardinality — one IP touching many accounts. Each is one ClickHouse query, run every minute.
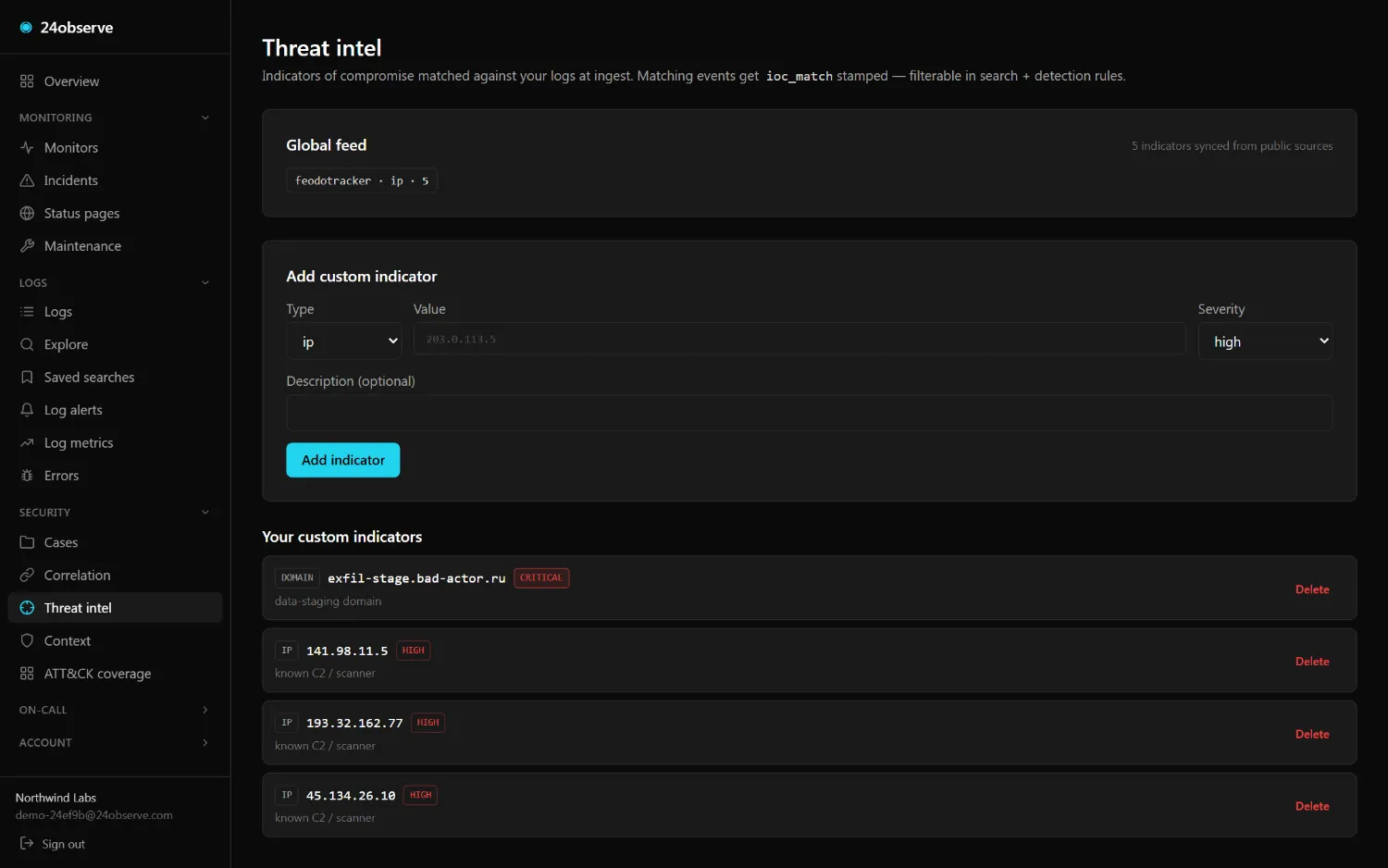
03 / THREAT INTEL
Every IP checked at ingest
Known-bad indicators, Tor exits, DNSBL listings, VPN and datacenter ranges — matched the moment an event lands. Bring your own IOCs (IP, domain, hash) or ride the built-in feeds.
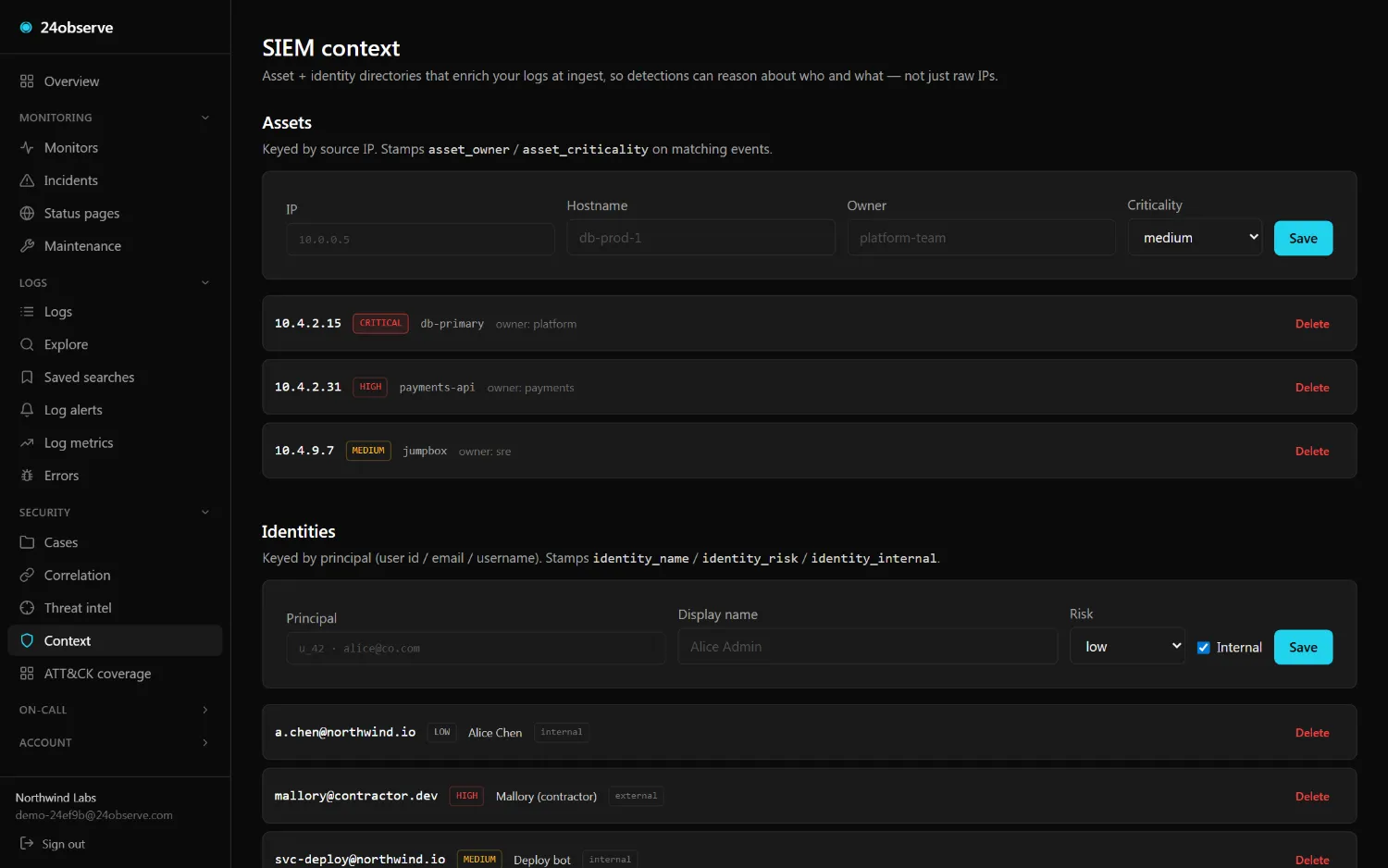
04 / ENRICH
Context on every event
GeoIP, ASN, identity risk, and asset criticality stamped inline at ingest — so asset_criticality:critical AND geo_country:RU is just a search, not a join.
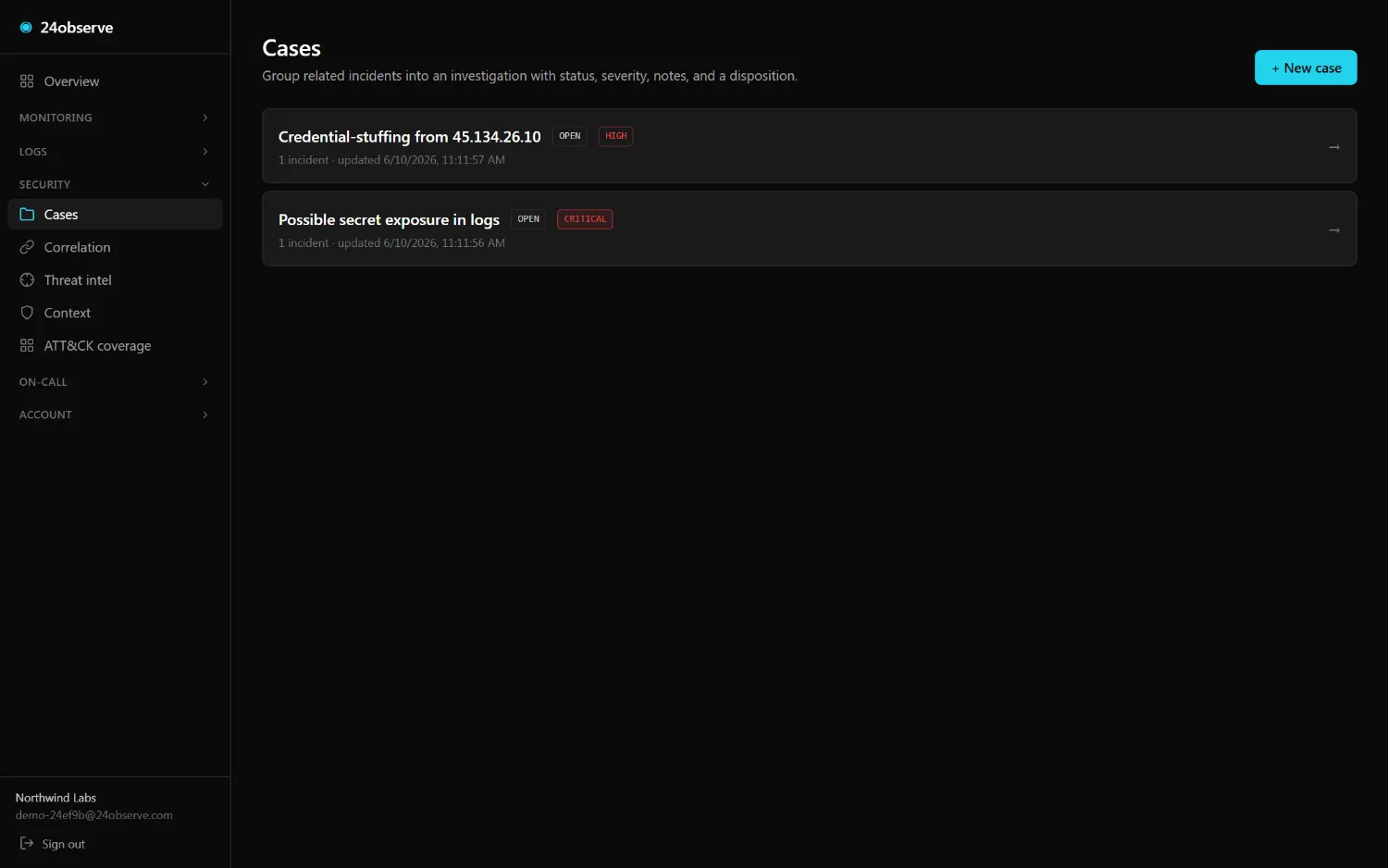
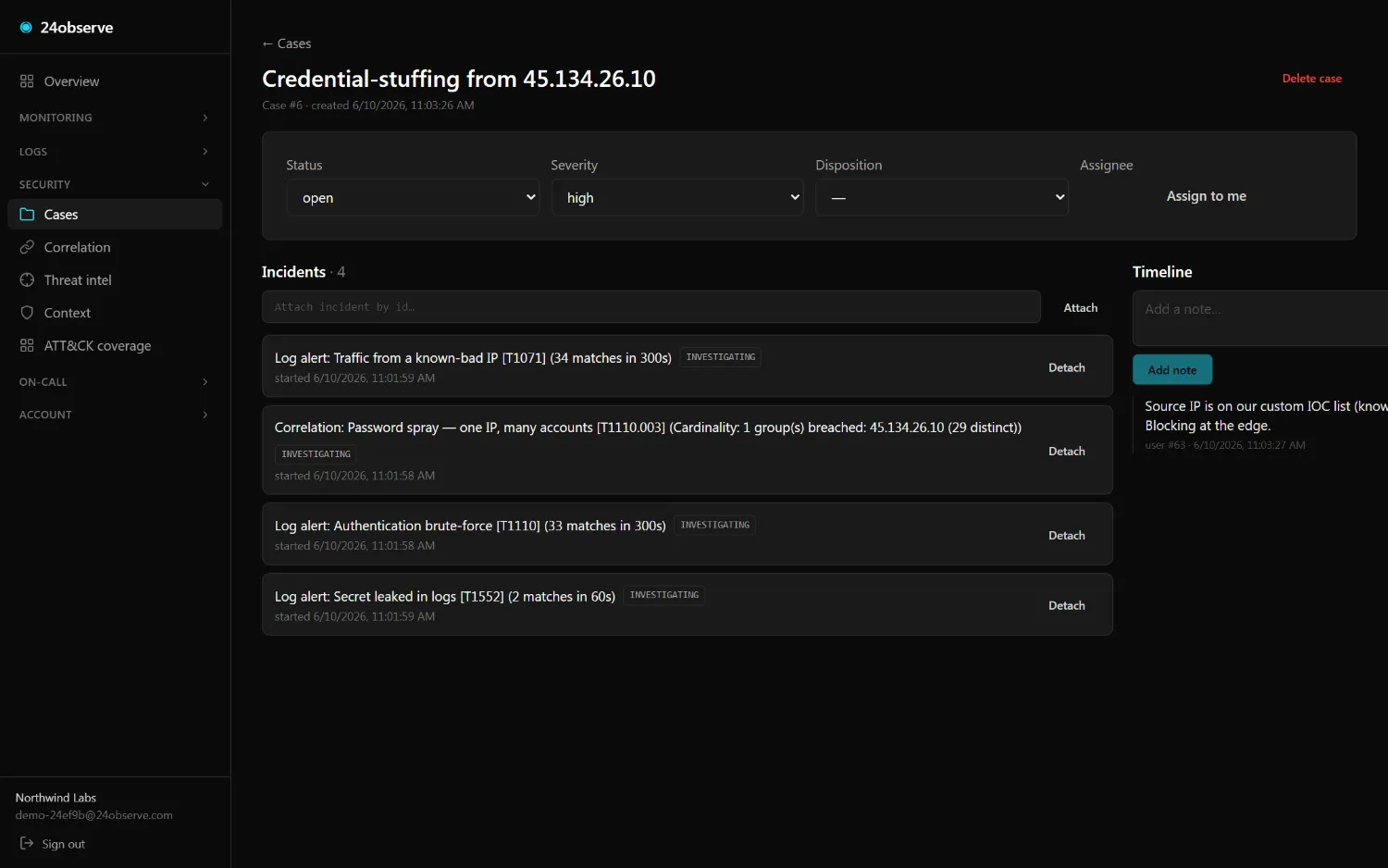
05 / INVESTIGATE
Security cases
Group incidents into one investigation — status, severity, assignee, a notes timeline, and a true-/false-positive disposition. The analyst workspace, not a shared spreadsheet.
06 / EXPORT
SIEM-ready out
Forward-cursor NDJSON export so Splunk, Datadog, or your own SIEM polls the trail gap-free. Signed webhooks route every detection straight to SOAR.
Every plan gets every detection — no "security tier", no per-GB intelligence meter.